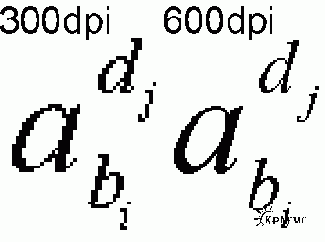Как почистить сканы книг? Часть 1.
В статье описана очистка сканов книг непосредственно после сканирования, перед дальнейшей обработкой. Речь будет идти только о черно-белых книгах (текст и штриховые рисунки). Обработку книг с цветными картинками нужно разбирать отдельно.
А зачем?
После сканирования книги её предполагается выкладывать в сеть (или хранить у себя на диске).
Здесь есть 2 пути:
1) Можно распознать сканы в программе OCR, например FineReader (FR).
Если качество оригинала хорошее, например распечатка на лазернике с размером шрифта 12pt, то FR прекрасно распознает её без всяких дополнительных мер. Но вот если распознавать нужно старую книжку, на желтой неровной бумаге, грязную и т. п… Тут предварительная очистка резко повысит качество распознавания, а это значит, что гораздо меньше труда и времени уйдет на вычитку, т.е. ручное исправление ошибок. Надо сказать, что встроенные в FR средства очистки картинки довольно примитивные, так что с плохими, зашумленными сканами он справляется неважно.
2) Можно хранить нераспознанной, в виде растровой картинки, в том или ином формате: DJVU, PDF, TIFF.
Здесь предварительная очистка ещё уместнее. Во-первых, очищенный скан гораздо приятнее и не так утомительно читать. Во-вторых, что ещё важнее, после очистки сканы гораздо, в десятки раз, лучше сжимаются в любой формат. Дело в том, что случайные точки на изображении (шум) практически не сжимаемы, особенно когда их много.
Для очистки изображений применяется много различных методов и программ, порой стоимостью в тысячи и десятки тысяч долларов. Я опишу простой и доступный способ, особенно ценный тем, что руками придется работать только с одной страницей книги, остальные можно обработать автоматически, основываясь на сохраненных параметрах.
1-й этап: сканирование
Сканировать книжку нужно обязательно в режиме grayscale (серый). Обратите внимание: сканировать в режиме b/w (черно-белый) нельзя! В режиме b/w дальнейшая обработка будет невозможна.
Можно сканировать в true image (полноцвет), но это сильно замедлит обработку, увеличит объем файлов, а особенного выигрыша не даст. Исключение составляют случаи, когда на страницах есть цветные пятна грязи, тут работа с цветом может сильно помочь.
Некоторые сканеры позволяют выбрать один из цветовых каналов (красный, зеленый, синий), который будет использоваться при сканировании в серый, есть и другие настройки и их также можно покрутить. Но не увлекайтесь, большая часть фич сканера просто обработка картинки драйвером. То же самое можно сделать в фотошопе, только куда лучше.
Попробуйте разные варианты, выбирать нужно тот, где изображение контрастнее, буквы выглядят более четкими. Если при этом мелких шумов (например, фактура бумаги) будет, в разумных пределах, больше -- это неважно, уберем потом.
Наоборот, если на бумаге есть крупные, размером в 2-3 буквы и больше, пятна, то нужно постараться подобрать настройки сканера так, чтобы эти пятна были бледными, по сравнению с буквами, пусть и ценой менее контрастных, по сравнению с другими вариантами букв.
Проще говоря, настраивайте сканер так:
1) Если крупных пятен нет, то главное сделать четкими буквы, а на шум особенно не глядеть.
2) Если крупные пятна есть, то главное их прибить, даже если буквы будут не такие уж четкие.
В том и другом случае нужно не перебарщивать, руководствуясь опытом и здравым смыслом.
Если вы пользуетесь для сканирования FR, то уберите в опциях сканирования «Очистить изображение», «Устранить искажение строк», «Делить развороты». Всё это вы сделаете потом, когда почистите сканы и втяните их обратно в FR. На этом этапе любая обработка изображения в FR только замедлит сканирование и ухудшит чистку изображения в более подходящих программах.
О выборе разрешения скана. Обычно книжки с текстом сканируют с разрешением 300dpi. Это подходящее значение для чистого текста, приличного качества полиграфии и не слишком мелкого шрифта, короче очередной бестселлер типа: "Глухой против Слепого". Но в этом случае и чистка изображения не требуется. При зашумленном изображении, мелком шрифте нужно сканировать с разрешением 600dpi. Это сильно облегчит очистку и качество окончательного файла, если вы не будете распознавать книгу, а сохраните в виде сжатого растра. Не беспокойтесь о величине окончательного файла. Хорошо почищенная книга с разрешением 600dpi при сжатии в DJVU дает файл немногим больших размеров, чем с разрешением 300dpi.
Растровая форма хранения книг особенно часто применяется для книг с формулами. В этом случае сканирование с разрешением 600dpi обязательно, иначе трудно будет разобрать индексы в формулах, отличить похожие буквы, например "омега" и w. А ведь в математике нередки вложенные индексы (индекс индекса). Там при сканировании с разрешением 300dpi вообще трудно что-либо разобрать, тем более распечатать. Вот смотрите:
Буквы i и j на картинке слева трудно отличить друг от друга. А ведь это не скан, а печать в файл. При сканировании всё будет гораздо хуже -- маленькая точка на бумаге и всё, и 2 балла на экзамене !
Таким образом:
Сканировать для наших целей нужно с разрешением 600dpi!
В крайнем случае, 400dpi.
Теперь нужно выбрать образцовую страницу для настройки программ обработки, чтобы остальные обработать автоматически, в пакетном режиме. Выберите самую обычную, типовую страницу, может быть слегка более грязную, чем в среднем.
Посмотрите все отсканенные страницы книги, может быть некоторые нужно пересканить.
Все сильно загрязненные, искаженные, с более мелким шрифтом, чем остальные, с очень крупными пятнами, с рисунками на всю или почти всю страницу и т.п. сразу положите в отдельную папку. Их проще обработать отдельно, по одной. Обычно таких немного.
Дальше приступим к обработке сканов последовательно в программе NeatImagePro+, потом в PhotoShop’е. Начнем с первой.
2-этап: NeatImagePro
Нам понадобится программа NeatImagePro+ (NI+) , у неё множество уникальных возможностей, например с её помощью можно делать замечательные "гламурные" картинки обнаженной натуры. Вот её сайт: www.neatimage.com. Но нам туда не надо, там её свободно не раздают. К счастью, у Вас есть я, а у нас всех Рапидшара:
Neat Image Pro+ Edition v5.0.5.0
пароль:))))))
Это не самая последняя версия, зато с лекарством и вполне рабочая.
NI+ работает следующим образом: выделяется характерный участок картинки с шумом, но без полезного изображения. Программа этот участок оценивает и "вычитает" шум из всей картинки.
Я закавычил "вычитает" потому, что на самом деле не "вычитает", а умножает, и не картинку на шум, а их двухмерные спектральные представления. Да и не умножает, если в школьном смысле… Но мы в эти дебри не полезем :-).
Главное окно программы организовано в виде вкладок:
1) Вкладка: Input Image
Про то, как загрузить файл в программу, я рассказывать не буду, замечу лишь, что NI+ не желает открывать 8-битный TIFF, если он сохранен, например из PhotoShop’а как индексированный 8-битный с палитрой, но нормально открывает, если TIFF сохранить как grayscale.
2) Вкладка: Device Noise Profile
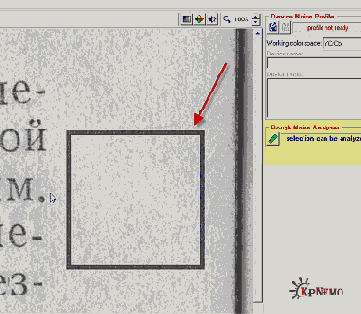
На этом этапе мы должны выбрать участок скана, где нет букв и рисунков, но есть характерные шумы. Обратите внимание: темные полосы около корешка или на краях тоже не должны попасть в наш выбор. На выделенный участок показывает стрелка на Рис. 1:
Рис. 1 (щелкнуть, чтобы увеличить)
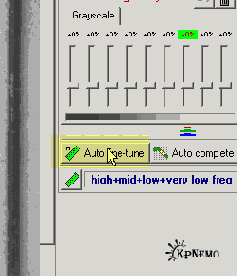
После того, как мы выделим подходящий участок, надо щелкнуть по кнопке "Rough Noise Analyzer" на левой панели, на Рис.1 подсвечена желтым. Некоторое время наблюдаем за синей полоской… и на левой панели, под упомянутой кнопкой, появятся дополнительные настройки (Рис. 2).
Рис. 2
Проще всего нажать на кнопочку "Auto fine-tune" (подсвечена желтым), и перейти к вкладке:
3) Вкладка: Noise Filter Settings
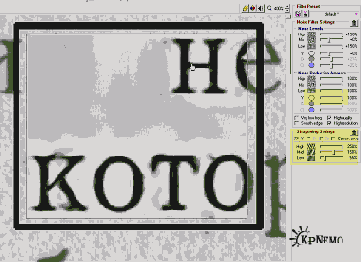
Здесь мы настроим фильтр так, чтобы сделать максимально четкими буквы и убить шумы. Перед настройкой фильтра нужно выделить участок подходящий участок с полезным изображением и увеличить его на весь экран. При выборе участка нужно руководствоваться следующими соображениями:
1) Брать нужно, по возможности, максимально зашумленный участок
2) Одновременно этот участок должен с наиболее мелким деталями полезного изображения, например с мелким шрифтом.
Поскольку мы обрабатываем не фотографию любимой кошки, а текст, то естественность изображения нас не волнует. Главное, чтобы буквы были почетче, а шума поменьше. Поэтому смело двигаем движки на левой половине панели и смотрим, что получается. Обращайте внимание на мелкие детали букв: хвостики, например сравнивайте "C" и "G"; внутренние участки букв, например в верхней части строчной "е".
Описывать действие каждого движка я не буду, проще пробовать и смотреть.
Рис. 3 (щелкнуть, чтобы увеличить)
На картинке (Рис. 3) изображен результат обработки, а положение движков и чекбоксов можно взять за точку отсчета при собственных экспериментах. В основном играйте движками в "Noise reduction Amounts", особенно движок "Y"; "Sharpening Settings". Эти участки левой панели на рисунке подсвечены желтым. Когда результат вам понравится, подвигайте прямоугольник Preview по всему изображению, чтоб прикинуть, как оно будет выглядеть в разных местах. Если все хорошо, сохраните полученный профиль фильтрации, он будет использован для пакетной обработки остальных страниц.
4) Вкладка: Output Image
Здесь вы можете нажать на Apply и посмотреть, что получилось. А если вы уверены, что настроили NI+ хорошо, то сразу переходите к пакетной обработке остальных страниц. Просто нажмите Esc, и вы попадете в окно пакетного обработчика.
5) Окно пакетного обработчика
File -> Bath, добавляете нужные страницы (не забудьте в "Filter Presets" пометить "Use specified preset" и выбрать сохраненный прежде, при настройке по образцовой странице пресет. Наконец можно запустить процесс обработки. Он долгий, поэтому запустите его на ночь, или, наоборот, с утра, перед уходом на работу.
Дальше нужно продолжить чистку в Фотошопе, но об этом в следующей части, которая будет опубликована, если эта вызовет интерес и желание продолжения у юзеров kpnemo.
|